Real-Time Data Processing With Actian Zen and Kafka Connectors
Johnson Varughese
July 17, 2024

Welcome back to the world of Actian Zen, a versatile and powerful edge data management solution designed to help you build low-latency embedded apps. In part 1 , we explored how to leverage BtrievePython to run Btrieve2 Python applications, using the Zen 16.0 Enterprise/Server Database Engine.
This is Part 2 of the quickstart blog series that focuses on helping embedded app developers get started with Actian Zen. In this blog post, we’ll walk through setting up a Kafka demo using Actian Zen, demonstrating how to manage and process real-time financial transactions seamlessly. This includes configuring environment variables, using an orchestration script, generating mock transaction data, leveraging Docker for streamlined deployment, and utilizing Docker Compose for orchestration.
Introduction to Actian Zen Kafka Connectors
In the dynamic world of finance, processing and managing real-time transactions efficiently is a must-have. Actian Zen’s Kafka Connectors offer a robust solution for streaming transaction data between financial systems and Kafka topics. The Actian Zen Kafka Connectors facilitate seamless integration between Actian Zen databases and Apache Kafka. These connectors support both source and sink operations, allowing you to stream data out of a Zen Btrieve database into Kafka topics or vice versa.
Source Connector
The Zen Source connector streams JSON data from a Zen Btrieve database into a Kafka topic. It employs change capture polling to pick up new data at user-defined intervals, ensuring that your Kafka topics are always updated with the latest information from your Zen databases.
Sink Connector
The Zen Sink connector streams JSON data from a Kafka topic into a Zen Btrieve database. You can choose to stream data into an existing database or create a new one when starting the connector.
Setting Up Environment Variables
Before diving into the configuration, it’s essential to set up the necessary environment variables. These variables ensure that your system paths and library paths are correctly configured, and that you accept the Zen End User License Agreement (EULA).
Here’s an example of the environment variables you need to set:
export PATH="/usr/local/actianzen/bin:/usr/local/actianzen/lib64:$PATH"
export LD_LIBRARY_PATH="/usr/local/actianzen/lib64:/usr/lib64:/usr/lib"
export CLASSPATH="/usr/local/actianzen/lib64"
export CONNECT_PLUGIN_PATH='/usr/share/java'
export ZEN_ACCEPT_EULA="YES"
Configuring the Kafka Connectors
The configuration parameters for the Kafka connectors are provided as key-value pairs. These configurations can be set via a properties file, the Kafka REST API, or programmatically. Here’s an example JSON configuration for a source connector:
{ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.Kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.Kafka.connect.storage.StringConverter", "value.converter": "org.apache.Kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }
You can also define user queries for more granular data filtering using the JSON query language detailed in the Btrieve2 API Documentation. For example, to filter for transactions greater than or equal to $1000:
"\"Transaction\":{\"Amount\":{\"$gte\":1000}}"
Orchestration Script: kafkasetup.py
The kafkasetup.py script automates the process of starting and stopping the Kafka connectors. Here’s a snippet showing how the script sets up connectors:
import requests import json def main(): requestMap = {} requestMap["Financial Transactions"] = ({ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }, "8083") for name, requestTuple in requestMap.items(): input("Press Enter to continue...") (request, port) = requestTuple print("Now starting " + name + " connector") try: r = requests.post("http://localhost:"+port+"/connectors", json=request) print("Response:", r.json) except Exception as e: print("ERROR: ", e) print("Finished setup!...") input("\n\nPress Enter to begin shutdown") for name, requestTuple in requestMap.items(): (request, port) = requestTuple try: r = requests.delete("http://localhost:"+port+"/connectors/"+request["name"]) except Exception as e: print("ERROR: ", e) if __name__ == "__main__": main()
When you run the script, it prompts you to start each connector one by one, ensuring everything is set up correctly.
Generating Transaction Data With data_generator.py
The data_generator.py script simulates financial transaction data, creating transaction records at specified intervals. Here’s a look at the core function:
import sys import os import signal import json import random from time import sleep from datetime import datetime sys.path.append("/usr/local/actianzen/lib64") import btrievePython as BP
class GracefulKiller:
kill_now = False def __init__(self): signal.signal(signal.SIGINT, self.exit_gracefully) signal.signal(signal.SIGTERM, self.exit_gracefully) def exit_gracefully(self, *args): self.kill_now = True def generate_transactions(): client = BP.BtrieveClient() assert(client != None) collection = BP.BtrieveCollection() assert(collection != None) collectionName = os.getenv("GENERATOR_DB_URI") rc = client.CollectionCreate(collectionName) rc = client.CollectionOpen(collection, collectionName) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) interval = int(os.getenv("GENERATOR_INTERVAL")) kill_condition = GracefulKiller() while not kill_condition.kill_now: transaction = { "Transaction": { "ID": random.randint(1000, 9999), "Amount": round(random.uniform(10.0, 5000.0), 2), "Currency": "USD", "Timestamp": str(datetime.now()) } } print(f"Generated transaction: {transaction}") documentId = collection.DocumentCreate(json.dumps(transaction)) if documentId < 0: print("DOCUMENT CREATE ERROR: " + BP.Btrieve.StatusCodeToString(collection.GetLastStatusCode())) sleep(interval) rc = client.CollectionClose(collection) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) if __name__ == "__main__": generate_transactions()
This script runs an infinite loop, continuously generating and inserting transaction data into a Btrieve collection.
Using Docker for Deployment
To facilitate this setup, we use a Docker container. Here’s the Dockerfile that sets up the environment to run our data generator script:
FROM actian/zen-client:16.00 USER root RUN apt update && apt install python3 -y COPY --chown=zen-svc:zen-data data_generator.py /usr/local/actianzen/bin ADD _btrievePython.so /usr/local/actianzen/lib64 ADD btrievePython.py /usr/local/actianzen/lib64 USER zen-svc CMD ["python3", "/usr/local/actianzen/bin/data_generator.py"]
This Dockerfile extends from the Actian Zen client image, installs Python, and includes the data generation script. By building and running this Docker container, we can generate and stream transaction data into Kafka topics as configured.
Docker Compose for Orchestration
To manage and orchestrate multiple containers, including Kafka, Zookeeper, and our data generator, we use Docker Compose. Here’s the docker-compose.yml file that brings everything together:
version: '3.8' services: zookeeper: image: wurstmeister/zookeeper:3.4.6 ports: - "2181:2181" kafka: image: wurstmeister/kafka:2.13-2.7.0 ports: - "9092:9092" environment: KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT KAFKA_LOG_RETENTION_HOURS: 1 KAFKA_MESSAGE_MAX_BYTES: 10485760 KAFKA_BROKER_ID: 1 volumes: - /var/run/docker.sock:/var/run/docker.sock actianzen: build: . environment: GENERATOR_DB_URI: "transactions.mkd" GENERATOR_LOCALE: "Austin" GENERATOR_INTERVAL: "5" volumes: - ./data:/usr/local/actianzen/data
This docker-compose.yml file sets up Zookeeper, Kafka, and our Actian Zen data generator in a single configuration. By running docker-compose up, we can spin up the entire stack and start streaming financial transaction data into Kafka topics in real-time.
Visualizing the Kafka Stream
To give you a better understanding of the data flow in this setup, here’s a diagram illustrating the Kafka stream:
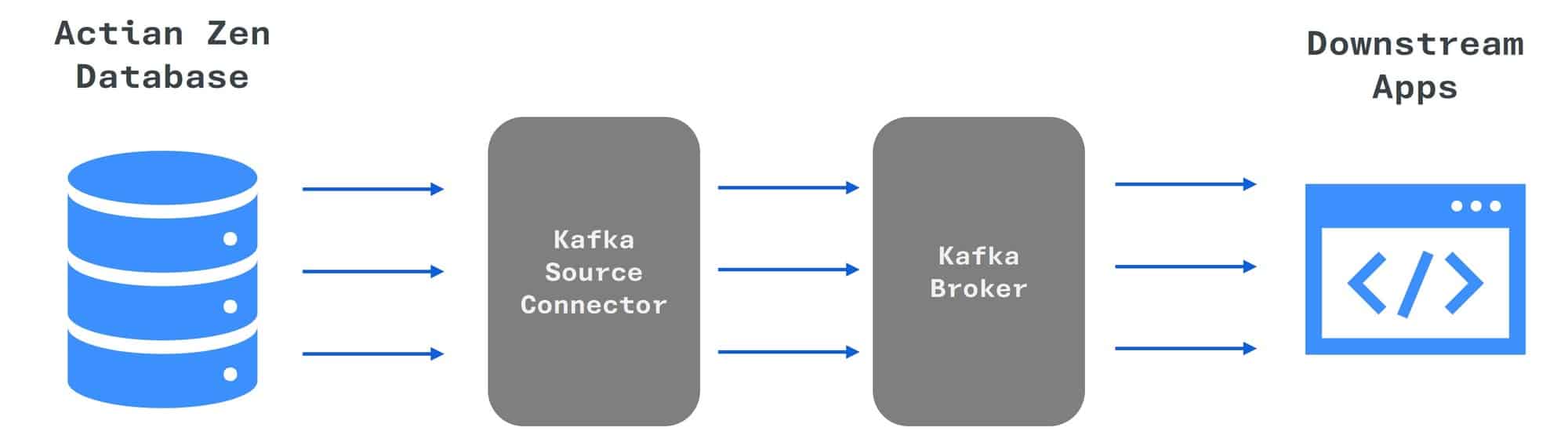
In this diagram, the financial transaction data flows from the Actian Zen database through the Kafka source connector into the Kafka topics. The data can then be consumed and processed by various downstream applications.
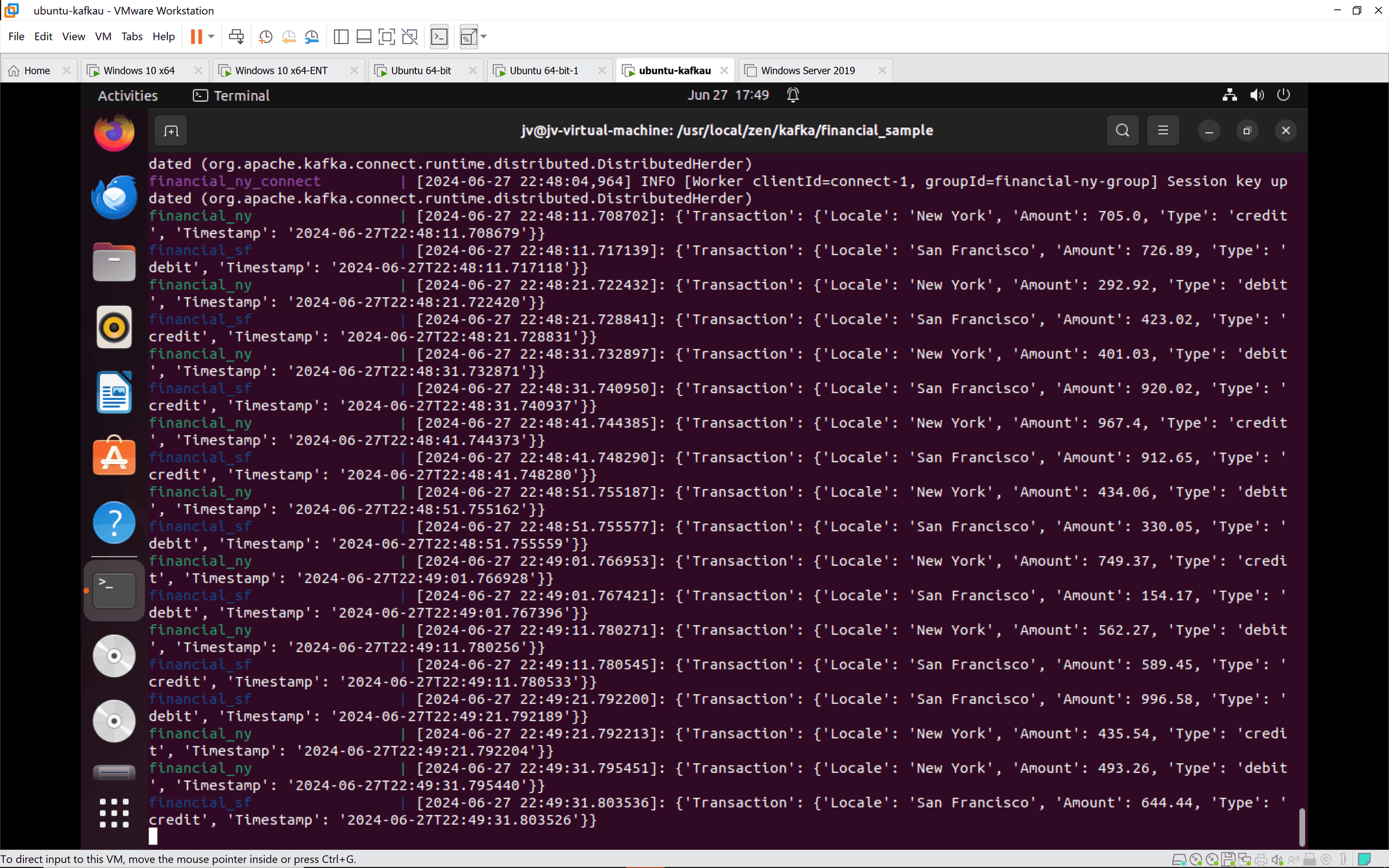
Kafka Connect: Kafka Connect instances are properly joining groups and syncing. Tasks and connectors are being configured and started as expected.
Financial Transactions: Transactions from both New York and San Francisco are being processed and logged correctly. The transactions include a variety of credit and debit actions with varying amounts and timestamps.
Conclusion
Integrating Actian Zen with Kafka Connectors provides a powerful solution for real-time data streaming and processing. By following this guide, you can set up a robust system to handle financial transactions, ensuring data is efficiently streamed, processed, and stored. This setup not only demonstrates the capabilities of Actian Zen and Kafka but also highlights the ease of deployment using Docker and Docker Compose. Whether you’re dealing with financial transactions or other data-intensive applications, this solution offers a scalable and reliable approach to real-time data management.
For further details and visual guides, refer to the Actian Academy and the comprehensive documentation. Happy coding!

Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live
- It’s all up to you – Change your delivery preferences to suit your needs